1. What are the different data types in Python and how are they used in DS problems?
Answer:
Python has several built-in data types, commonly used in data structure problems:
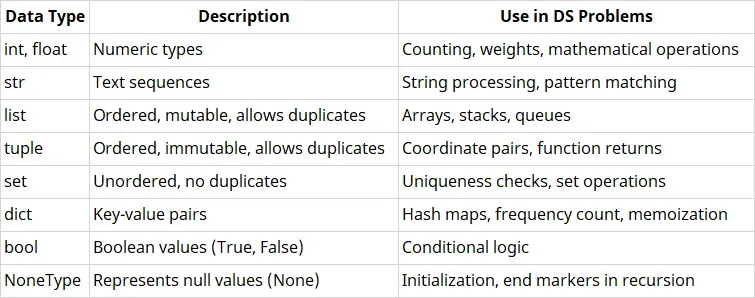
Advanced types include collections.deque, defaultdict, Counter, OrderedDict for optimized DS operations.
2. How is memory managed in Python during list and dictionary operations?
Answer:
Python uses automatic memory management via the Python Memory Manager, which includes:
- Private heap space: All objects and data structures are stored here.
- Dynamic resizing:
- Lists grow using over-allocation (extra space reserved).
- Dicts grow using rehashing and resizing as elements increase.
List Memory:
- Internally uses a resizable array.
- Amortized O(1) time for append due to geometric resizing.
Dictionary Memory:
- Uses a hash table.
- Keys are hashed, and collisions are resolved using open addressing.
Python automatically manages memory via:
- Reference counting
- Garbage collector for cyclic references
3. What is the difference between list, tuple, and set in Python?
Answer:
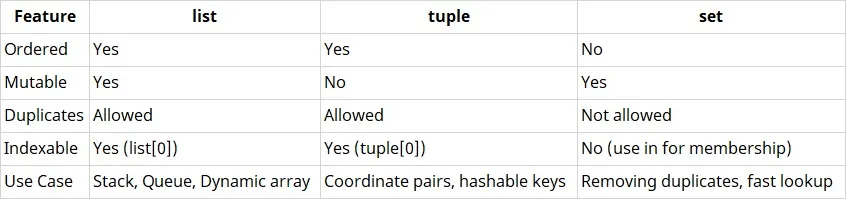
4. Explain the concept of mutability with respect to Python data structures.
Answer:
Mutability refers to whether the object’s content can be changed after creation.

Examples:
lst = [1, 2]; lst[0] = 5 # Mutable
tup = (1, 2); tup[0] = 5 # Error (immutable)
In DS problems:
- Use immutable types for hashable keys in sets/dicts.
- Use mutable types for dynamic updates.
5. How does Python manage references and garbage collection?
Answer:
Python uses reference counting and a cyclic garbage collector.
- Reference Counting: Each object keeps track of how many references point to it.
- When count = 0 → memory is deallocated.
- Garbage Collector (gc module):
- Detects and collects cyclic references (e.g., mutually referring lists).
- Uses generational GC:
- Objects are grouped in generations (0, 1, 2) based on age.
- Younger objects are collected more frequently.
Example:
import gc
gc.collect() # Manually trigger garbage collection
6. What are Python iterators and generators? How do they support DS operations?
Answer:
Iterator: Object with __iter__() and __next__() methods.
lst = [1, 2, 3]
it = iter(lst)
print(next(it)) # Output: 1
Generator: A special iterator using yield instead of return.
Benefits:
- Memory-efficient (lazy evaluation)
- Useful for large data streams (e.g., infinite series, tree traversal)
Example:
def countdown(n):
while n > 0:
yield n
n -= 1
Used in:
- Tree traversals
- Streaming data
- Efficient backtracking
7. What is the difference between is and == in Python?
Answer:

Use is
- To compare identity (e.g., is None)
- When checking for singleton objects
Use ==
- When comparing values/contents
8. Explain how slicing works in Python and give DS use cases.
Answer:
Slicing Syntax: sequence[start:stop:step]
Examples:
lst = [10, 20, 30, 40, 50]
lst[1:4] # [20, 30, 40]
lst[::-1] # [50, 40, 30, 20, 10] → reverse
Use Cases in DS:
- Reversing strings/lists
- Copying arrays (arr[:])
- Extracting subarrays or substrings
- Sliding window technique (arr[i:i+k])
9. How do you implement custom sorting using key and lambda in Python?
Answer:
Python’s sorted() and list.sort() accept a key argument for custom logic.
Examples:
# Sort by length
words = ['banana', 'apple', 'kiwi']
sorted_words = sorted(words, key=len)
# Sort by second element of tuple
pairs = [(1, 3), (2, 1), (5, 2)]
pairs.sort(key=lambda x: x[1])
Real-world DS Use:
- Sorting by frequency
- Custom comparators (e.g., sort by absolute value, sort strings by custom order)
10. Explain time complexity of built-in Python operations (append, pop, insert, sort).
Answer:
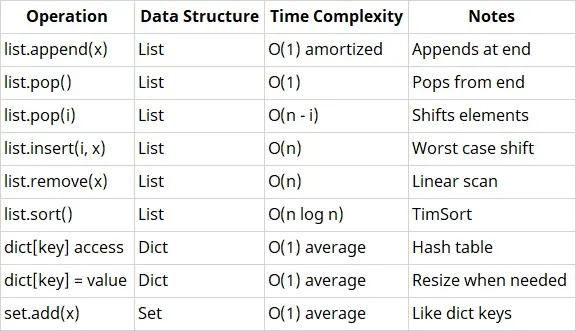
Note: Worst-case dict/set operations may degrade to O(n) due to hash collisions, but are rare with good hash functions.
11. Implement two-pointer approach to reverse a string in Python
Answer:
def reverse_string(s):
s = list(s) # Convert to list for in-place modification
left, right = 0, len(s) - 1
while left < right:
s[left], s[right] = s[right], s[left]
left += 1
right -= 1
return ''.join(s)
# Test
print(reverse_string("python")) # Output: "nohtyp"
12. How do you remove duplicates from a list while preserving order?
Answer:
def remove_duplicates(lst):
seen = set()
result = []
for item in lst:
if item not in seen:
seen.add(item)
result.append(item)
return result
# Test
print(remove_duplicates([1, 2, 2, 3, 1, 4])) # Output: [1, 2, 3, 4]
13. Given a rotated sorted array, write a function to search a target element
Answer:
def search_rotated_array(nums, target):
left, right = 0, len(nums) - 1
while left <= right:
mid = (left + right) // 2
if nums[mid] == target:
return mid
# Left half is sorted
if nums[left] <= nums[mid]:
if nums[left] <= target < nums[mid]:
right = mid - 1
else:
left = mid + 1
# Right half is sorted
else:
if nums[mid] < target <= nums[right]:
left = mid + 1
else:
right = mid - 1
return -1 # Not found
# Test
print(search_rotated_array([4, 5, 6, 7, 0, 1, 2], 0)) # Output: 4
14. Implement Kadane’s algorithm to find the maximum subarray sum
Answer:
def max_subarray_sum(nums):
max_sum = current_sum = nums[0]
for num in nums[1:]:
current_sum = max(num, current_sum + num)
max_sum = max(max_sum, current_sum)
return max_sum
# Test
print(max_subarray_sum([-2,1,-3,4,-1,2,1,-5,4])) # Output: 6
15. Check if two strings are anagrams using Python dictionaries
Answer:
def are_anagrams(s1, s2):
if len(s1) != len(s2):
return False
count = {}
for c in s1:
count[c] = count.get(c, 0) + 1
for c in s2:
if c not in count:
return False
count[c] -= 1
if count[c] < 0:
return False
return True
# Test
print(are_anagrams("listen", "silent")) # Output: True16. How would you implement run-length encoding of a string?
Answer:
def run_length_encode(s):
if not s:
return ""
result = []
count = 1
prev = s[0]
for c in s[1:]:
if c == prev:
count += 1
else:
result.append(prev + str(count))
prev = c
count = 1
result.append(prev + str(count))
return ''.join(result)
# Test
print(run_length_encode("aaabbc")) # Output: "a3b2c1"
17. Implement string compression using counts of repeated characters
Answer:
def compress_string(s):
if not s:
return ""
compressed = []
count = 1
prev = s[0]
for c in s[1:]:
if c == prev:
count += 1
else:
compressed.append(prev + str(count))
prev = c
count = 1
compressed.append(prev + str(count))
result = ''.join(compressed)
# Return original if compression doesn't reduce size
return result if len(result) < len(s) else s
# Test
print(compress_string("aabcccccaaa")) # Output: "a2b1c5a3"
18. Given a list of numbers, return indices of two numbers that add to a target (Two Sum)
Answer:
def two_sum(nums, target):
index_map = {} # num → index
for i, num in enumerate(nums):
complement = target - num
if complement in index_map:
return [index_map[complement], i]
index_map[num] = i
return [] # No valid pair found
# Test
print(two_sum([2, 7, 11, 15], 9)) # Output: [0, 1]
19. Explain sliding window technique with an example problem
Answer:
Sliding Window is used to optimize problems with contiguous subarrays.
Example Problem: Find the maximum sum of any subarray of size k.
def max_sum_subarray_k(nums, k):
window_sum = sum(nums[:k])
max_sum = window_sum
for i in range(k, len(nums)):
window_sum += nums[i] - nums[i - k]
max_sum = max(max_sum, window_sum)
return max_sum
# Test
print(max_sum_subarray_k([1, 4, 2, 10, 2, 3, 1, 0, 20], 4)) # Output: 24
20. Implement group anagrams problem using Python
Answer:
from collections import defaultdict
def group_anagrams(strs):
anagrams = defaultdict(list)
for word in strs:
# Sort characters to form a key
key = ''.join(sorted(word))
anagrams[key].append(word)
return list(anagrams.values())
# Test
print(group_anagrams(["eat", "tea", "tan", "ate", "nat", "bat"]))
# Output: [['eat', 'tea', 'ate'], ['tan', 'nat'], ['bat']]
21. Implement a Singly Linked List in Python
Answer:
class Node:
def __init__(self, data):
self.data = data
self.next = None
class SinglyLinkedList:
def __init__(self):
self.head = None
def insert_end(self, data):
new_node = Node(data)
if not self.head:
self.head = new_node
return
curr = self.head
while curr.next:
curr = curr.next
curr.next = new_node
def display(self):
curr = self.head
while curr:
print(curr.data, end=" -> ")
curr = curr.next
print("None")
22. Reverse a Linked List (Iterative and Recursive)
Answer:
Iterative Approach
def reverse_iterative(head):
prev = None
curr = head
while curr:
next_node = curr.next
curr.next = prev
prev = curr
curr = next_node
return prev
Recursive Approach
def reverse_recursive(head):
if not head or not head.next:
return head
new_head = reverse_recursive(head.next)
head.next.next = head
head.next = None
return new_head
23. Detect a Cycle in a Linked List (Floyd’s Algorithm)
Answer:
def has_cycle(head):
slow = fast = head
while fast and fast.next:
slow = slow.next
fast = fast.next.next
if slow == fast:
return True
return False
24. Find the Middle of a Linked List
Answer:
def find_middle(head):
slow = fast = head
while fast and fast.next:
slow = slow.next
fast = fast.next.next
return slow # Middle node
25. Merge Two Sorted Linked Lists
Answer:
def merge_sorted_lists(l1, l2):
dummy = Node(0)
tail = dummy
while l1 and l2:
if l1.data <= l2.data:
tail.next = l1
l1 = l1.next
else:
tail.next = l2
l2 = l2.next
tail = tail.next
tail.next = l1 or l2
return dummy.next
26. Remove the Nth Node from the End of a Linked List
Answer:
def remove_nth_from_end(head, n):
dummy = Node(0)
dummy.next = head
fast = slow = dummy
for _ in range(n):
fast = fast.next
while fast.next:
fast = fast.next
slow = slow.next
slow.next = slow.next.next
return dummy.next
27. Check if a Linked List is a Palindrome
Answer:
def is_palindrome(head):
if not head or not head.next:
return True
# Find middle
slow = fast = head
while fast and fast.next:
slow = slow.next
fast = fast.next.next
# Reverse second half
prev = None
while slow:
next_node = slow.next
slow.next = prev
prev = slow
slow = next_node
# Compare halves
left, right = head, prev
while right:
if left.data != right.data:
return False
left = left.next
right = right.next
return True
28. Add Two Numbers Represented by Linked Lists
Answer:
def add_two_numbers(l1, l2):
dummy = Node(0)
curr = dummy
carry = 0
while l1 or l2 or carry:
v1 = l1.data if l1 else 0
v2 = l2.data if l2 else 0
total = v1 + v2 + carry
carry = total // 10
curr.next = Node(total % 10)
curr = curr.next
if l1: l1 = l1.next
if l2: l2 = l2.next
return dummy.next
29. Flatten a Multilevel Linked List
Answer:
Assume each node has next and child pointers (like a doubly linked list with children).
class MultiLevelNode:
def __init__(self, data):
self.data = data
self.next = None
self.child = None
def flatten(head):
if not head:
return head
dummy = MultiLevelNode(0)
stack = [head]
prev = dummy
while stack:
curr = stack.pop()
prev.next = curr
prev = curr
if curr.next:
stack.append(curr.next)
if curr.child:
stack.append(curr.child)
curr.child = None
return dummy.next
30. Sort a Linked List Using Merge Sort
Answer:
def merge_sort(head):
if not head or not head.next:
return head
# Split the list into two halves
slow, fast = head, head.next
while fast and fast.next:
slow = slow.next
fast = fast.next.next
mid = slow.next
slow.next = None
left = merge_sort(head)
right = merge_sort(mid)
return merge_sorted_lists(left, right)
Note: merge_sorted_lists() is already defined in question 25.
31. Implement a Stack Using list and collections.deque
Answer:
Using list:
class StackList:
def __init__(self):
self.stack = []
def push(self, x):
self.stack.append(x) # O(1)
def pop(self):
return self.stack.pop() if self.stack else None # O(1)
def peek(self):
return self.stack[-1] if self.stack else None
def is_empty(self):
return not self.stack
Using collections.deque:
from collections import deque
class StackDeque:
def __init__(self):
self.stack = deque()
def push(self, x):
self.stack.append(x)
def pop(self):
return self.stack.pop() if self.stack else None
def peek(self):
return self.stack[-1] if self.stack else None
def is_empty(self):
return not self.stack
32. Evaluate a Postfix Expression Using Stack
Answer:
def evaluate_postfix(expression):
stack = []
for token in expression.split():
if token.isdigit():
stack.append(int(token))
else:
b = stack.pop()
a = stack.pop()
if token == '+': stack.append(a + b)
elif token == '-': stack.append(a - b)
elif token == '*': stack.append(a * b)
elif token == '/': stack.append(int(a / b)) # Truncate towards 0
return stack[0]
# Test
print(evaluate_postfix("2 3 1 * + 9 -")) # Output: -4
33. Implement a Queue Using Two Stacks
Answer:
class QueueTwoStacks:
def __init__(self):
self.in_stack = []
self.out_stack = []
def enqueue(self, x):
self.in_stack.append(x)
def dequeue(self):
if not self.out_stack:
while self.in_stack:
self.out_stack.append(self.in_stack.pop())
return self.out_stack.pop() if self.out_stack else None
def peek(self):
if not self.out_stack:
while self.in_stack:
self.out_stack.append(self.in_stack.pop())
return self.out_stack[-1] if self.out_stack else None
def is_empty(self):
return not self.in_stack and not self.out_stack
34. Design a Min-Stack (Retrieve Min in O(1))
Answer:
class MinStack:
def __init__(self):
self.stack = []
self.min_stack = []
def push(self, val):
self.stack.append(val)
if not self.min_stack or val <= self.min_stack[-1]:
self.min_stack.append(val)
def pop(self):
if self.stack:
val = self.stack.pop()
if val == self.min_stack[-1]:
self.min_stack.pop()
def top(self):
return self.stack[-1] if self.stack else None
def get_min(self):
return self.min_stack[-1] if self.min_stack else None
35. Check for Balanced Parentheses Using Stack
Answer:
def is_balanced(expr):
stack = []
pairs = {')': '(', '}': '{', ']': '['}
for char in expr:
if char in '([{':
stack.append(char)
elif char in ')]}':
if not stack or stack[-1] != pairs[char]:
return False
stack.pop()
return not stack
# Test
print(is_balanced("{[()]}")) # Output: True
36. Implement an LRU Cache Using OrderedDict
Answer:
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity):
self.cache = OrderedDict()
self.capacity = capacity
def get(self, key):
if key not in self.cache:
return -1
self.cache.move_to_end(key) # Recently used
return self.cache[key]
def put(self, key, value):
if key in self.cache:
self.cache.move_to_end(key)
self.cache[key] = value
if len(self.cache) > self.capacity:
self.cache.popitem(last=False) # Remove least recently used
37. Implement a Circular Queue in Python
Answer:
class CircularQueue:
def __init__(self, k):
self.queue = [None] * k
self.capacity = k
self.front = self.rear = -1
def enqueue(self, val):
if (self.rear + 1) % self.capacity == self.front:
return False # Full
if self.front == -1:
self.front = 0
self.rear = (self.rear + 1) % self.capacity
self.queue[self.rear] = val
return True
def dequeue(self):
if self.front == -1:
return False # Empty
if self.front == self.rear:
self.front = self.rear = -1
else:
self.front = (self.front + 1) % self.capacity
return True
def Front(self):
return -1 if self.front == -1 else self.queue[self.front]
def Rear(self):
return -1 if self.rear == -1 else self.queue[self.rear]
def is_empty(self):
return self.front == -1
def is_full(self):
return (self.rear + 1) % self.capacity == self.front
38. Solve the Sliding Window Maximum Using deque
Answer:
from collections import deque
def sliding_window_max(nums, k):
dq = deque()
result = []
for i in range(len(nums)):
while dq and dq[0] < i - k + 1:
dq.popleft()
while dq and nums[dq[-1]] < nums[i]:
dq.pop()
dq.append(i)
if i >= k - 1:
result.append(nums[dq[0]])
return result
# Test
print(sliding_window_max([1,3,-1,-3,5,3,6,7], 3)) # Output: [3,3,5,5,6,7]
39. What is the Difference Between collections.deque and queue.Queue?
Answer:
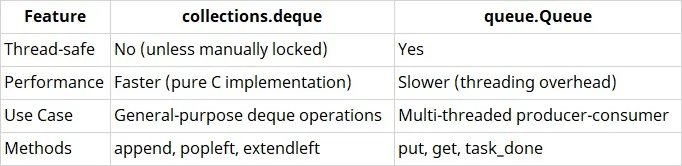
Use deque for single-threaded fast queue/stack.
Use queue.Queue for multi-threaded applications.
40. Simulate a Browser Back/Forward Feature Using Two Stacks
Answer:
class Browser:
def __init__(self):
self.back_stack = []
self.forward_stack = []
self.current = None
def visit(self, url):
if self.current:
self.back_stack.append(self.current)
self.current = url
self.forward_stack.clear()
def back(self):
if self.back_stack:
self.forward_stack.append(self.current)
self.current = self.back_stack.pop()
return self.current
def forward(self):
if self.forward_stack:
self.back_stack.append(self.current)
self.current = self.forward_stack.pop()
return self.current
# Test
b = Browser()
b.visit("A")
b.visit("B")
b.visit("C")
print(b.back()) # Output: B
print(b.back()) # Output: A
print(b.forward()) # Output: B