1. What is Generative AI and how is it different from Discriminative AI?
Answer:
Generative AI refers to models that learn the distribution of data and generate new, realistic data samples (e.g., images, audio, text).
Discriminative AI refers to models that learn to distinguish between different categories of data by learning decision boundaries.

2. Explain the working principle of a Generative Adversarial Network (GAN).
Answer:
A GAN consists of two neural networks:
- Generator (G): Learns to generate realistic fake data.
- Discriminator (D): Learns to distinguish real data from fake data.
Training Process:
- The Generator takes random noise (latent vector) as input and generates fake data.
- The Discriminator receives both real and fake data and tries to classify them correctly.
- Both models compete:
- Generator tries to fool the Discriminator.
- Discriminator tries to detect fake data.
- Training continues until the Discriminator cannot distinguish between real and generated samples.
Mathematically:
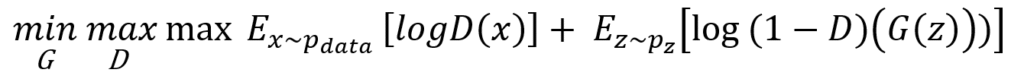
3. What is the role of the Generator and Discriminator in GANs?
Answer:

- The Generator is trained to maximize the Discriminator’s error.
- The Discriminator is trained to minimize classification error between real and fake samples.
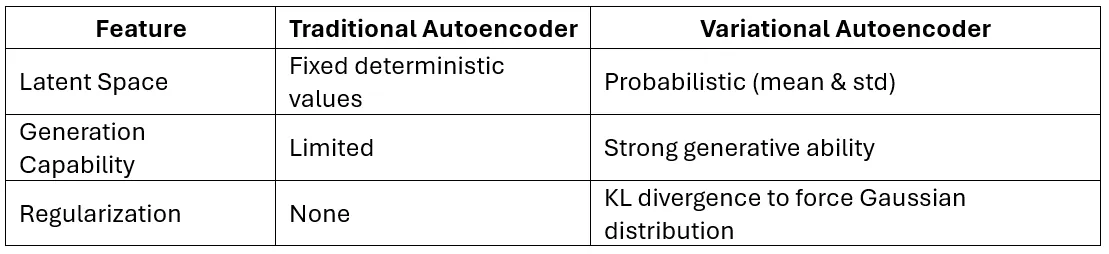
4. How does Variational Autoencoder (VAE) work? Compare with traditional Autoencoders.
Answer:
A VAE is a type of probabilistic autoencoder that models the latent space with a probability distribution (usually Gaussian).
Steps:
- Encoder: Maps input to a mean μ\muμ and standard deviation σ\sigmaσ.
- Sampling: Uses the reparameterization trick:
- Decoder: Reconstructs input from sampled zzz.
Loss Function:
Loss=Reconstruction Loss+KL Divergence
5. When should you use GAN vs. VAE in real-world projects?
Answer:
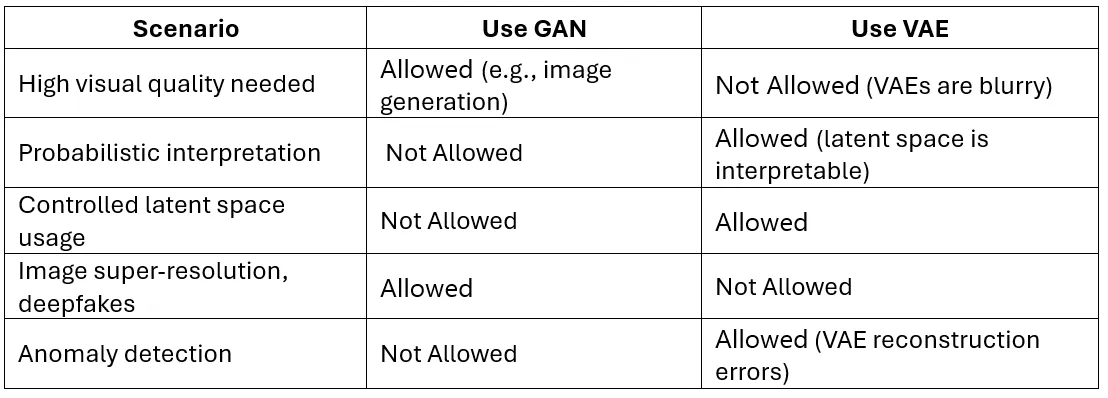
Summary:
- Use GANs for sharp, realistic generation, e.g., face synthesis.
- Use VAEs for reconstructive tasks or semi-supervised learning where latent space is meaningful.
6. What are the limitations and risks of using Generative AI in production environments?
Answer:
Limitations:
- Instability in training (especially GANs)
- Mode collapse
- Requires large datasets and compute
- Difficult to evaluate objectively
Risks:
- Bias replication from training data
- Misinformation and deepfakes
- Copyright or ethical issues
- Hallucinations in generated content
- Security concerns (e.g., adversarial attacks)
7. How do you evaluate the performance of a generative model?
Answer:
Quantitative Metrics:
- Inception Score (IS) – Measures diversity and confidence of generated images.
- Fréchet Inception Distance (FID) – Measures distance between feature distributions of real and fake data.
- Precision & Recall for GANs – Measures quality vs. coverage.
Qualitative:
- Human evaluation
- t-SNE visualization of latent space
- Diversity check (mode coverage)
Example: FID in Python
from pytorch_fid import fid_score
fid_score.calculate_fid_given_paths([real_path, fake_path])
8. What is mode collapse in GANs and how can it be mitigated?
Answer:
Mode Collapse occurs when the Generator produces limited diversity, generating similar outputs for different noise inputs.
Mitigation Techniques:
- Use Mini-batch Discrimination
- Add Noise to Discriminator
- Use Unrolled GANs
- Use Wasserstein GAN (WGAN) with Gradient Penalty
- Apply Feature Matching Loss
9. How does the latent space of a generative model help in controlled generation?
Answer:
The latent space is a compressed representation of the data distribution.
Uses:
- Interpolation: Generate smooth transitions between outputs.
- Vector arithmetic: Semantic manipulation (e.g., “smiling face” – “neutral face” + “female”)
- Attribute control: Generate samples with specific features by steering in latent directions.
In VAE and GANs (e.g., StyleGAN):
z = np.random.normal(size=(1, latent_dim))
generated_image = generator.predict(z)
10. Explain diffusion models and how they are different from GANs and VAEs.
Answer:
Diffusion Models learn to generate data by reversing a gradual noise process.
Working Principle:
- Forward process: Add Gaussian noise to data over many time steps.
- Reverse process: Learn to denoise step-by-step using a neural network.
Differences:
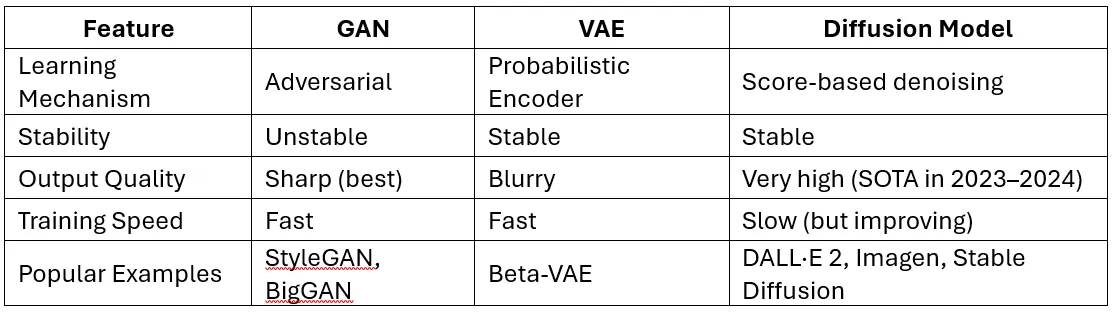
Key Strength of Diffusion:
- High-fidelity generation
- Rich control over generation (via conditioning or text prompts)
11. How do you implement a basic GAN using TensorFlow in Python?
Answer:
import tensorflow as tf
from tensorflow.keras import layers
# Generator
def build_generator():
model = tf.keras.Sequential([
layers.Dense(128, activation='relu', input_shape=(100,)),
layers.Dense(784, activation='sigmoid')
])
return model
# Discriminator
def build_discriminator():
model = tf.keras.Sequential([
layers.Dense(128, activation='relu', input_shape=(784,)),
layers.Dense(1, activation='sigmoid')
])
return model
# Compile
generator = build_generator()
discriminator = build_discriminator()
discriminator.compile(optimizer='adam', loss='binary_crossentropy')
# GAN Model
z = layers.Input(shape=(100,))
img = generator(z)
discriminator.trainable = False
valid = discriminator(img)
gan = tf.keras.Model(z, valid)
gan.compile(optimizer='adam', loss='binary_crossentropy')
12. Write code to create a simple VAE using PyTorch.
Answer:
import torch
from torch import nn
import torch.nn.functional as F
class VAE(nn.Module):
def __init__(self, input_dim=784, hidden_dim=400, latent_dim=20):
super(VAE, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
self.fc_dec = nn.Linear(latent_dim, hidden_dim)
self.fc_out = nn.Linear(hidden_dim, input_dim)
def encode(self, x):
h = F.relu(self.fc1(x))
return self.fc_mu(h), self.fc_logvar(h)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
h = F.relu(self.fc_dec(z))
return torch.sigmoid(self.fc_out(h))
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
13. How would you generate synthetic images using a pre-trained GAN in Python?
Answer:
import torch
from torchvision.utils import save_image
# Load pre-trained generator
generator = torch.load("generator.pth", map_location="cpu")
generator.eval()# Generate latent vectors
z = torch.randn(64, 100) # batch size = 64
with torch.no_grad():
fake_images = generator(z)
# Save samples
save_image(fake_images.view(64, 1, 28, 28), 'synthetic.png', nrow=8)
14. How do you create a custom training loop for a GAN in TensorFlow 2.x?
Answer:
def train_step(real_images):
batch_size = tf.shape(real_images)[0]
noise = tf.random.normal([batch_size, 100])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
fake_images = generator(noise)
real_output = discriminator(real_images)
fake_output = discriminator(fake_images)
gen_loss = tf.keras.losses.binary_crossentropy(tf.ones_like(fake_output), fake_output)
disc_loss_real = tf.keras.losses.binary_crossentropy(tf.ones_like(real_output), real_output)
disc_loss_fake = tf.keras.losses.binary_crossentropy(tf.zeros_like(fake_output), fake_output)
disc_loss = disc_loss_real + disc_loss_fake
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
gen_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
disc_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
15. What Python libraries are best suited for generative tasks?
Answer:
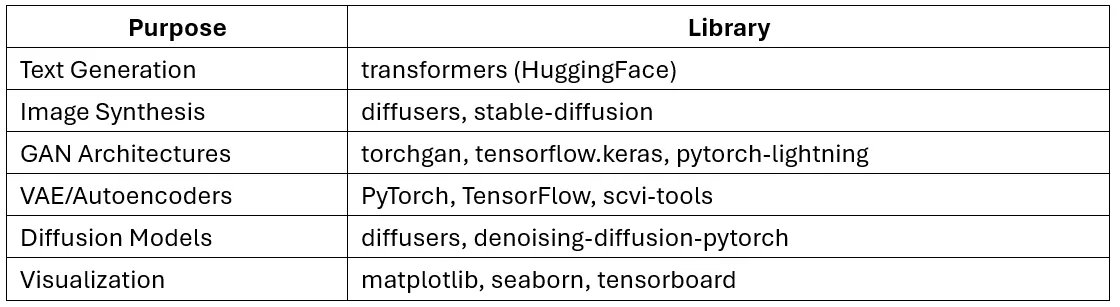
16. Implement code to visualize the latent space interpolation of a VAE.
Answer:
import numpy as np
import matplotlib.pyplot as plt
def interpolate(model, z_start, z_end, steps=10):
vectors = [z_start * (1 - alpha) + z_end * alpha for alpha in np.linspace(0, 1, steps)]
reconstructions = [model.decode(torch.tensor(vec).float()).detach().numpy() for vec in vectors]
plt.figure(figsize=(15, 2))
for i, img in enumerate(reconstructions):
plt.subplot(1, steps, i + 1)
plt.imshow(img.reshape(28, 28), cmap='gray')
plt.axis('off')
plt.show()
17. Write a Python function to calculate the Fréchet Inception Distance (FID) score.
Answer:
from pytorch_fid import fid_score
def calculate_fid(real_path, fake_path, batch_size=50, device='cuda'):
score = fid_score.calculate_fid_given_paths(
[real_path, fake_path],
batch_size,
device,
dims=2048
)
return score
18. How do you use HuggingFace transformers for text generation using GPT models?
Answer:
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
model.eval()
input_text = "Once upon a time"
inputs = tokenizer.encode(input_text, return_tensors="pt")
outputs = model.generate(inputs, max_length=50, do_sample=True, top_k=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
19. Show how to finetune GPT-2 using your own dataset in Python.
Answer:
from transformers import Trainer, TrainingArguments, GPT2Tokenizer, GPT2LMHeadModel, TextDataset, DataCollatorForLanguageModeling
tokenizer = GPT2Tokenizer.from_pretrained(“gpt2”)
model = GPT2LMHeadModel.from_pretrained(“gpt2”)
# Prepare dataset
def load_dataset(file_path):
return TextDataset(
tokenizer=tokenizer,
file_path=file_path,
block_size=128
)
train_dataset = load_dataset("train.txt")
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
training_args = TrainingArguments(
output_dir="./gpt2-finetuned",
overwrite_output_dir=True,
num_train_epochs=3,
per_device_train_batch_size=2,
save_steps=500,
save_total_limit=2
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=data_collator
)
trainer.train()
20. How can you use Stable Diffusion in Python to generate realistic images from text?
Answer:
from diffusers import StableDiffusionPipelineimport torch
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
torch_dtype=torch.float16
).to("cuda")
prompt = "A watercolor painting of a sunset over mountains"
image = pipe(prompt).images[0]
image.save("watercolor_painting.png")
21. How do Transformer architectures like GPT and BERT support generative tasks?
Answer:

Summary:
- GPT (Generative Pre-trained Transformer) uses a decoder-only Transformer and supports left-to-right generation (e.g., ChatGPT).
- BERT (Bidirectional Encoder Representations from Transformers) is an encoder-only model and excels at classification, QA, etc., but not free-form generation.
Only GPT-like (decoder-based) or encoder-decoder models like T5, BART, and FLAN-T5 are suitable for text generation.
22. Write Python code using HuggingFace to generate responses from a fine-tuned GPT-2 model.
Answer:
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# Load tokenizer and fine-tuned model
tokenizer = GPT2Tokenizer.from_pretrained('./gpt2-finetuned')
model = GPT2LMHeadModel.from_pretrained('./gpt2-finetuned')# Encode prompt
prompt = "What are the benefits of using transformers in NLP?"
inputs = tokenizer(prompt, return_tensors="pt")
# Generate output
output = model.generate(
inputs["input_ids"],
max_length=100,
do_sample=True,
top_k=50,
temperature=0.7
)
# Decode and print
print(tokenizer.decode(output[0], skip_special_tokens=True))
23. Explain the concept of temperature and top-k sampling in text generation.
Answer:
- Temperature (τ) controls randomness in output:
- τ = 1.0 → standard
- τ < 1.0 → conservative, focused
- τ > 1.0 → more diverse, riskier
- Formula: softmax(logits / temperature)
- Top-k Sampling restricts generation to the top k probable tokens:
- Only top k tokens are considered for sampling.
- Reduces unlikely/random tokens.
Combined use helps balance creativity and coherence.
24. What is the difference between greedy decoding, beam search, and nucleus sampling?
Answer:
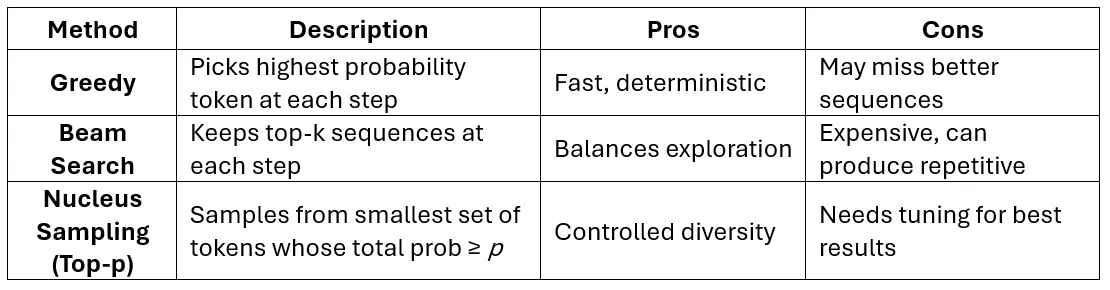
25. How can you prevent repetition and incoherent outputs during text generation?
Answer:
Strategies:
- Penalty settings:
- repetition_penalty (e.g., 1.2) discourages repeated tokens
- no_repeat_ngram_size (e.g., 2) prevents repeating n-grams
output = model.generate(
inputs["input_ids"],
max_length=100,
no_repeat_ngram_size=2,
repetition_penalty=1.2,
temperature=0.7,
top_k=50
)
- Use beam search + diversity penalty
- Use fine-tuned models on domain-specific data
26. What are prompt engineering techniques for improving LLM output?
Answer:
Effective Techniques:
- Zero-shot prompting: Just give the task
- “Translate this sentence to French: ‘Hello, how are you?’”
- Few-shot prompting: Provide examples
- “Q: What’s 2+2?\nA: 4\nQ: What’s 3+3?\nA:”
- Chain-of-thought prompting**:
- Add intermediate reasoning steps.
- “Let’s solve step by step.”
- Role prompting:
- “You are a helpful legal assistant. Summarize this document.”
- Instruction tuning (e.g., FLAN models)
- Trained to follow specific prompts better.
27. How do you use LangChain to build a custom Generative AI pipeline in Python?
Answer:
from langchain import PromptTemplate, LLMChain
from langchain.llms import HuggingFacePipeline
from transformers import pipeline
# Load LLM
hf_pipeline = pipeline("text-generation", model="gpt2")
llm = HuggingFacePipeline(pipeline=hf_pipeline)# Prompt template
template = PromptTemplate.from_template("Generate a startup idea for: {topic}")# Chain setup
chain = LLMChain(prompt=template, llm=llm)
# Run
response = chain.run(topic="AI in Education")
print(response)
LangChain simplifies building LLM-powered apps by chaining:
- Prompts
- Retrieval
- Memory
- Tools
- Agents
28. What are embeddings, and how are they used in LLM-powered search and generation tasks?
Answer:
Embeddings are dense vector representations of text, capturing semantic meaning.
Use Cases:
- Semantic search: Match queries with documents by vector similarity
- Context injection: Use retrieved info to augment prompts in RAG
- Clustering / classification
Generate using HuggingFace:
from transformers import AutoTokenizer, AutoModel
import torch
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
inputs = tokenizer("Generative AI is powerful", return_tensors="pt", truncation=True)
with torch.no_grad():
embedding = model(**inputs).last_hidden_state.mean(dim=1)
29. How do you generate context-aware responses using Retrieval-Augmented Generation (RAG)?
Answer:
RAG combines:
- Retrieval from a document database
- Augmented prompting of an LLM with the retrieved context
Pipeline:
- User query → convert to embedding
- Search vector DB (e.g., FAISS, Pinecone)
- Inject context into prompt
- Generate response with LLM
Using LangChain + FAISS:
from langchain.chains import RetrievalQA
from langchain.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
# Load embeddings and retriever
embedding = HuggingFaceEmbeddings()
doc_store = FAISS.load_local("my_index", embedding)
retriever = doc_store.as_retriever()
# Build chain
rag_chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
response = rag_chain.run("Explain Generative AI in simple words.")
30. Explain how Reinforcement Learning with Human Feedback (RLHF) improves LLM outputs.
Answer:
RLHF is a three-step process:
- Pretrain a base LLM (e.g., GPT) on large text corpus
- Collect human-labeled responses to rank model outputs
- Train a reward model to mimic human preference
- Fine-tune the base LLM using Proximal Policy Optimization (PPO)
Benefits:
- Reduces toxic, biased, or harmful outputs
- Aligns LLM with human intent
- Powers models like ChatGPT, Claude, and Gemini
RLHF bridges the gap between large-scale pretraining and real-world utility by making LLMs safer, more aligned, and conversationally accurate.
31. How do you train a DCGAN to generate handwritten digits (MNIST) using Python?
Answer:
import torch
from torch import nn, optim
from torchvision import datasets, transforms
from torchvision.utils import save_image
# Dataset
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
loader = torch.utils.data.DataLoader(datasets.MNIST('.', download=True, transform=transform), batch_size=128, shuffle=True)
# Generator
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d(100, 256, 7, 1, 0),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.ConvTranspose2d(256, 128, 4, 2, 1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.ConvTranspose2d(128, 1, 4, 2, 1),
nn.Tanh()
)
def forward(self, x): return self.main(x)
# Discriminator
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Sequential(
nn.Conv2d(1, 64, 4, 2, 1),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, 4, 2, 1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Flatten(),
nn.Linear(128*7*7, 1),
nn.Sigmoid()
)
def forward(self, x): return self.main(x)
# Training
G, D = Generator().cuda(), Discriminator().cuda()
opt_G = optim.Adam(G.parameters(), 0.0002, betas=(0.5, 0.999))
opt_D = optim.Adam(D.parameters(), 0.0002, betas=(0.5, 0.999))
criterion = nn.BCELoss()
for epoch in range(10):
for real, _ in loader:
real = real.cuda()
batch_size = real.size(0)
noise = torch.randn(batch_size, 100, 1, 1).cuda()
fake = G(noise)
# Train D
D_real = D(real)
D_fake = D(fake.detach())
loss_D = criterion(D_real, torch.ones_like(D_real)) + criterion(D_fake, torch.zeros_like(D_fake))
opt_D.zero_grad(); loss_D.backward(); opt_D.step()
# Train G
output = D(fake)
loss_G = criterion(output, torch.ones_like(output))
opt_G.zero_grad(); loss_G.backward(); opt_G.step()
save_image(fake[:64], f”dcgan_epoch_{epoch}.png”, nrow=8, normalize=True)
32. Implement image-to-image translation using CycleGAN in Python.
Answer:
from diffusers import CycleDiffusionPipeline
import torch
pipe = CycleDiffusionPipeline.from_pretrained("CompVis/cyclegan-horse2zebra").to("cuda")
image_path = "horse.jpg"
result = pipe(prompt="", image=image_path).images[0]
result.save("zebra_output.png")For full custom CycleGANs, use PyTorch implementations like:
33. What is StyleGAN? How is it used for face generation and artistic style transfer?
Answer:
- StyleGAN (Style-based GAN) introduced by NVIDIA uses a style-based generator architecture that allows fine-grained control over generated image attributes.
- It separates content (structure) and style (texture) via AdaIN layers.
- Applications:
- High-resolution face generation (e.g., thispersondoesnotexist.com)
- Art synthesis, caricatures
- Morphing and interpolation of face features
Pre-trained StyleGAN2 example (using NVIDIA’s implementation):
git clone- https://github.com/NVlabs/stylegan2-ada-pytorch.git
cd stylegan2-ada-pytorch
python generate.py --outdir=out --trunc=1 --seeds=600-605 --network=pretrained_model.pkl
34. How can you use diffusers library to generate images using text prompts?
Answer:
from diffusers import StableDiffusionPipeline
import torch
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4").to("cuda")
prompt = "A futuristic city skyline at sunset in cyberpunk style"
image = pipe(prompt).images[0]
image.save("cyberpunk.png")
You can also use stable-diffusion-xl or openjourney models from HuggingFace.
35. Implement super-resolution using a generative model in PyTorch.
Answer:
from ISR.models import RRDN
from PIL import Image
import numpy as np
model = RRDN(weights='gans')
img = Image.open('low_res.jpg')
sr_img = model.predict(np.array(img))
Image.fromarray(sr_img).save("super_res.jpg")
For PyTorch, you can also use:
- ESRGAN: Enhanced Super-Resolution GAN
- Real-ESRGAN: Real-world image enhancement
36. How do conditional GANs (cGANs) work, and how are they implemented in Python?
Answer:
- cGANs take both noise and a label as input to generate class-specific outputs.
- Generator: G(z, y)
- Discriminator: D(x, y)
Implementation (concept):
# Input: random noise + class label
z = torch.randn(batch_size, latent_dim)
labels = torch.randint(0, 10, (batch_size,))
label_embedding = embedding_layer(labels)
input = torch.cat([z, label_embedding], dim=1)
Use case: Digit generation by class, image-to-image translation, segmentation maps.
37. What are applications of GANs in medical image synthesis and augmentation?
Answer:
- Data Augmentation: Generate more training samples for rare disease conditions.
- Cross-Modality Translation: CT ↔ MRI using CycleGAN
- Lesion Synthesis: Create synthetic tumors to improve detection models
- Segmentation Enhancement: Augment under-represented tissue types
- Privacy-preserving synthetic data for research sharing
Examples
- MedGAN: Synthesis for MRI
- Pix2Pix: Label-to-image generation for pathology
38. How do you ensure diversity and realism in image generation?
Answer:
Diversity:
- Use latent space sampling with truncation=1.0
- Avoid mode collapse (use Wasserstein GAN, gradient penalty)
- Add input noise or use dropout in generator
Realism:
- Train with high-quality datasets
- Use Perceptual Loss / VGG-based Loss
- Evaluate with FID, IS, and LPIPS
39. Write a Python program to create deepfake-like image generation using pre-trained models.
Answer:
from deepface import DeepFace
from PIL import Image
# Swap faces using DeepFace
result = DeepFace.swap("source.jpg", "target.jpg", detector_backend="opencv")
Image.fromarray(result).save("deepfake_result.jpg")For advanced face-swapping, use:
- SimSwap: https://github.com/neuralchen/SimSwap
- FaceFusion or DeepFaceLab
40. Explain how DreamBooth and LoRA (Low-Rank Adaptation) help in custom image generation.
Answer:
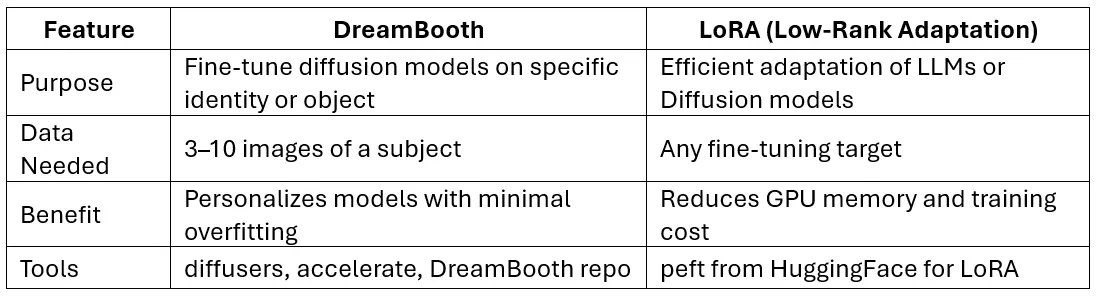
DreamBooth Example
accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5" \
--instance_prompt="a photo of sks person" \
--instance_data_dir="./data/person" \
--output_dir="./dreambooth-person"
LoRA with diffusers
from peft import get_peft_model, LoraConfig
lora_config = LoraConfig(r=8, lora_alpha=16, target_modules=["attn"], lora_dropout=0.1)
model = get_peft_model(model, lora_config)
41. What are the key evaluation metrics for generative models (FID, IS, BLEU, ROUGE)?
Answer:
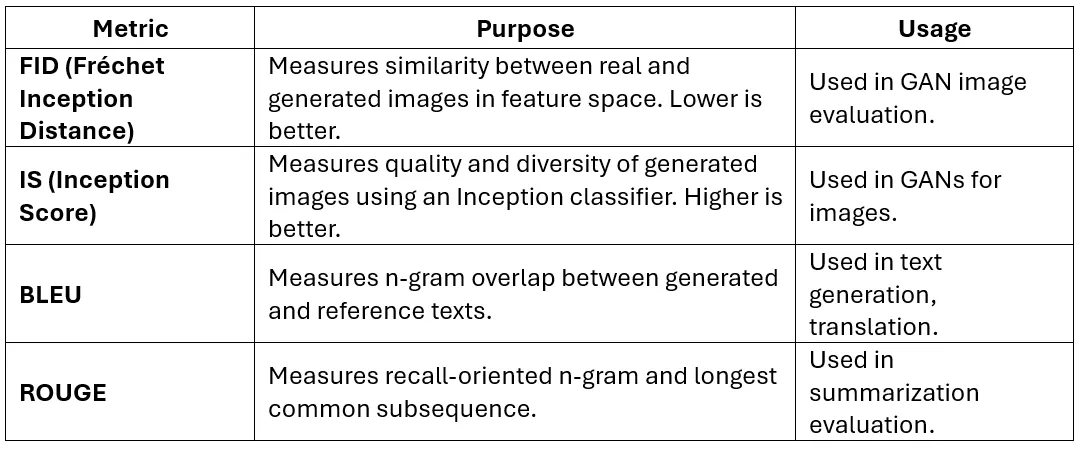
42. How do you handle overfitting in generative models?
Answer:
Strategies:
- Use data augmentation (especially for small datasets).
- Apply dropout in the generator and discriminator.
- Add noise to real and fake inputs (label smoothing or Gaussian noise).
- Use early stopping based on validation metrics.
- Introduce regularization (e.g., L2, gradient penalty in WGAN-GP).
- Monitor diversity metrics (avoid mode collapse).
43. What are the best practices to tune hyperparameters in GAN training?
Answer:
Best Practices:
- Learning rate: Use 2e-4 for both generator and discriminator.
- β1 for Adam: Use 0.5 (instead of default 0.9) for stability.
- Batch size: 64 or 128 commonly used.
- Label smoothing: Use real labels as 0.9 instead of 1.0.
- Noise injection: Add noise to inputs or discriminator targets.
- Monitor loss curves carefully:
- D loss ≈ 0.5, G loss stable → good equilibrium.
44. Implement early stopping for a GAN using custom training loops.
patience = 5
best_fid = float('inf')
wait = 0
for epoch in range(100):
train_gan_one_epoch(...)
current_fid = calculate_fid(real_path, fake_path)
if current_fid < best_fid:
best_fid = current_fid
wait = 0
save_model(generator, ‘best_g.pth’)
else:
wait += 1
if wait >= patience:
print(f”Early stopping at epoch {epoch}”)
break
45. How do you use TensorBoard to track GAN training progress in Python?
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
for epoch in range(num_epochs):
...
writer.add_scalar("Loss/Generator", g_loss.item(), epoch)
writer.add_scalar("Loss/Discriminator", d_loss.item(), epoch)
if epoch % 10 == 0:
fake_images = generator(fixed_noise)
writer.add_images(“Generated Images”, fake_images, epoch)
writer.close()
Launch with tensorboard –logdir=runs/ to visualize.
46. How do you perform data augmentation to improve generative model performance?
from torchvision import transforms
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.RandomCrop(28, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
Notes:
- Helps avoid overfitting.
- Creates diverse input space.
- Especially important for cGANs, Pix2Pix, CycleGAN.
47. What is Wasserstein GAN (WGAN) and how does it improve training stability?
Answer:
- WGAN replaces binary cross-entropy loss with the Wasserstein (Earth Mover’s) distance.
- It uses a critic instead of a discriminator and removes the sigmoid output.
- Benefits:
- Stable training
- Continuous loss (non-saturating)
- No mode collapse
- Enforces Lipschitz continuity using weight clipping or gradient penalty (WGAN-GP).
# Loss example
loss_D = -(torch.mean(D(real)) - torch.mean(D(fake)))
loss_G = -torch.mean(D(fake))
48. Write Python code to visualize generated samples after each epoch.
Answer:
from torchvision.utils import save_image
import os
def save_generated_samples(generator, epoch, latent_dim=100):
os.makedirs("samples", exist_ok=True)
z = torch.randn(64, latent_dim, 1, 1).to(device)
with torch.no_grad():
fake = generator(z)
save_image(fake, f'samples/epoch_{epoch}.png', nrow=8, normalize=True)
49. How do you apply transfer learning to improve generative model performance?
Answer:
Approaches:
- Fine-tune a pre-trained generator (e.g., StyleGAN, Stable Diffusion).
- Freeze early layers, retrain later layers on custom data.
- Use pretrained encoders (e.g., ResNet, VGG) in conditional GANs or autoencoders.
- Use DreamBooth or LoRA for personalization.
# Freeze first layers
for layer in generator.features[:5]:
for param in layer.parameters():
param.requires_grad = False
50. How can you optimize inference time of generative models for real-time applications?
Techniques:
- Model quantization (e.g., float32 → int8 using ONNX/TensorRT).
- Model pruning to remove redundant weights.
- Use ONNX Runtime, TorchScript, or TensorRT for deployment.
- Enable mixed precision inference (float16) with autocast.
# Example: Convert model to TorchScript
traced_gen = torch.jit.trace(generator.eval(), example_input)
traced_gen.save("generator_optimized.pt")
51. How do you deploy a generative AI model using FastAPI or Flask?
Answer:
Using FastAPI (recommended for speed & async support):
from fastapi import FastAPI
from pydantic import BaseModel
from transformers import pipeline
app = FastAPI()
generator = pipeline("text-generation", model="gpt2")
class Prompt(BaseModel):
text: str
@app.post("/generate")
def generate_text(prompt: Prompt):
result = generator(prompt.text, max_length=100, do_sample=True)[0]["generated_text"]
return {"output": result}
Run using:
uvicorn app:app –reload
Using Flask:
from flask import Flask, request, jsonify
from transformers import pipeline
app = Flask(__name__)
generator = pipeline("text-generation", model="gpt2")
@app.route('/generate', methods=['POST'])
def generate():
prompt = request.json['text']
output = generator(prompt, max_length=100)[0]['generated_text']
return jsonify({'output': output})
52. What are use cases of Generative AI in content creation and marketing?
Answer:
Use Cases:
- Blog/article generation (GPT, Jasper, Copy.ai)
- Product descriptions & ad copywriting
- Image/video creation for campaigns (DALL·E, Stable Diffusion)
- Email personalization
- Customer personas and targeting strategies
- Idea brainstorming & social media captions
Generative AI automates ideation, personalization, and creativity at scale.
53. How would you implement a chatbot using GPT and LangChain in Python?
Answer:
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0.7)
memory = ConversationBufferMemory()
chatbot = ConversationChain(llm=llm, memory=memory)
response = chatbot.predict(input="What are the benefits of generative AI?")
print(response)
For non-OpenAI models, use HuggingFacePipeline with LangChain. You can also integrate retrievers, tools, or APIs to expand capabilities.
54. What security concerns exist with deploying LLMs and GANs in production?
Answer:
Key Concerns:
- Prompt injection attacks
- Toxic or harmful output (bias, hate speech)
- Deepfakes and misinformation
- Data leakage (e.g., model memorizing training data)
- Denial of service (DoS) via long inputs
Mitigations:
- Input sanitization & token limits
- Use of content filters and moderation APIs
- Human-in-the-loop review
- Logging & monitoring
- Rate limiting and auth for APIs
55. How do you use Gradio or Streamlit to create a web UI for generative models?
Answer:
Gradio Example (GPT Text Generator)
import gradio as gr
from transformers import pipeline
generator = pipeline("text-generation", model="gpt2")
def generate_text(prompt):
return generator(prompt, max_length=100, do_sample=True)[0]["generated_text"]
gr.Interface(fn=generate_text, inputs="text", outputs="text").launch()
Streamlit Example
import streamlit as st
from transformers import pipeline
generator = pipeline("text-generation", model="gpt2")
st.title("Text Generator")
prompt = st.text_input("Enter your prompt:")
if st.button("Generate"):
result = generator(prompt, max_length=100, do_sample=True)[0]["generated_text"]
st.write(result)
56. How can you implement a recommendation system enhanced with Generative AI?
Answer:
Approach:
- Use collaborative or content-based filtering for base recommendations.
- Enhance with generative models:
- Use GPT to generate explanations, product summaries, or tips.
- Use VAE to model latent user/item spaces.
- Use prompt-based generation:
“User likes A, B. Suggest similar items with reasons.”
Example using GPT for explanation
from transformers import pipeline
generator = pipeline("text-generation", model="gpt2")
prompt = "Recommend a book similar to 'Generative AI' and explain why."
print(generator(prompt, max_length=100)[0]['generated_text'])
57. Explain how to use Google Colab to train and visualize generative models.
Answer:
Steps:
- Open https://colab.research.google.com
- Select GPU via: Runtime > Change Runtime Type > GPU
- Install required packages.
!pip install torch torchvision matplotlib
- Train your model using GPU-accelerated code.
- Visualize using:
import matplotlib.pyplot as plt
plt.imshow(generated_image.squeeze().cpu().numpy(), cmap=’gray’)
- Save and export:
from google.colab import files
files.download(“model.pth”)
58. How do you handle GPU/TPU memory optimization while training large generative models?
Answer:
Techniques:
- Use mixed-precision training with torch.cuda.amp
- Use gradient checkpointing
- Reduce batch size
- Avoid storing unnecessary tensors
- Use with torch.no_grad() during validation/inference
- Use offloading with libraries like DeepSpeed, HuggingFace Accelerate, or xFormers
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for inputs in dataloader:
optimizer.zero_grad()
with autocast():
loss = model(inputs)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
59. What are ethical concerns around AI-generated content and how do you handle them?
Answer:
Concerns:
- Misinformation & deepfakes
- Plagiarism / copyright
- Bias reinforcement
- Lack of accountability
- Misuse in fraud, impersonation, or manipulation
Solutions:
- Transparency: Declare AI usage.
- Use of watermarks or content tracing.
- Human review before publishing.
- Apply filters (toxicity, bias detection).
- Follow AI ethics frameworks (e.g., EU AI Act, OpenAI’s usage guidelines).
60. Explain how to build a multi-modal application that uses both text and image generation.
Answer
Components:
- Text-to-Image: Stable Diffusion or DALL·E
- Text Generation: GPT-2, GPT-3, FLAN-T5, LLaMA
- Optional: Audio (e.g., TTS) or Video
Example (using Gradio):
import gradio as gr
from diffusers import StableDiffusionPipeline
from transformers import pipeline
# Models
text_gen = pipeline("text-generation", model="gpt2")
img_gen = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5").to("cuda")
def generate_both(prompt):
story = text_gen(prompt, max_length=50, do_sample=True)[0]['generated_text']
image = img_gen(prompt).images[0]
return story, image
gr.Interface(fn=generate_both, inputs="text", outputs=["text", "image"]).launch()